 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Language Models with Self-Consistent Natural Language Explanations
Jun 09, 2025Large language models (LLMs) seem to offer an easy path to interpretability: just ask them to explain their decisions. Yet, studies show that these post-hoc explanations often misrepresent the true decision process, as revealed by mismatches in feature importance. Despite growing evidence of this inconsistency, no systematic solutions have emerged, partly due to the high cost of estimating feature importance, which limits evaluations to small datasets. To address this, we introduce the Post-hoc Self-Consistency Bank (PSCB) - a large-scale benchmark of decisions spanning diverse tasks and models, each paired with LLM-generated explanations and corresponding feature importance scores. Analysis of PSCB reveals that self-consistency scores barely differ between correct and incorrect predictions. We also show that the standard metric fails to meaningfully distinguish between explanations. To overcome this limitation, we propose an alternative metric that more effectively captures variation in explanation quality. We use it to fine-tune LLMs via Direct Preference Optimization (DPO), leading to significantly better alignment between explanations and decision-relevant features, even under domain shift. Our findings point to a scalable path toward more trustworthy, self-consistent LLMs.
Gap the (Theory of) Mind: Sharing Beliefs About Teammates' Goals Boosts Collaboration Perception, Not Performance
May 06, 2025


In human-agent teams, openly sharing goals is often assumed to enhance planning, collaboration, and effectiveness. However, direct communication of these goals is not always feasible, requiring teammates to infer their partner's intentions through actions. Building on this, we investigate whether an AI agent's ability to share its inferred understanding of a human teammate's goals can improve task performance and perceived collaboration. Through an experiment comparing three conditions-no recognition (NR), viable goals (VG), and viable goals on-demand (VGod) - we find that while goal-sharing information did not yield significant improvements in task performance or overall satisfaction scores, thematic analysis suggests that it supported strategic adaptations and subjective perceptions of collaboration. Cognitive load assessments revealed no additional burden across conditions, highlighting the challenge of balancing informativeness and simplicity in human-agent interactions. These findings highlight the nuanced trade-off of goal-sharing: while it fosters trust and enhances perceived collaboration, it can occasionally hinder objective performance gains.
Interactive Explanations for Reinforcement-Learning Agents
Apr 07, 2025As reinforcement learning methods increasingly amass accomplishments, the need for comprehending their solutions becomes more crucial. Most explainable reinforcement learning (XRL) methods generate a static explanation depicting their developers' intuition of what should be explained and how. In contrast, literature from the social sciences proposes that meaningful explanations are structured as a dialog between the explainer and the explainee, suggesting a more active role for the user and her communication with the agent. In this paper, we present ASQ-IT -- an interactive explanation system that presents video clips of the agent acting in its environment based on queries given by the user that describe temporal properties of behaviors of interest. Our approach is based on formal methods: queries in ASQ-IT's user interface map to a fragment of Linear Temporal Logic over finite traces (LTLf), which we developed, and our algorithm for query processing is based on automata theory. User studies show that end-users can understand and formulate queries in ASQ-IT and that using ASQ-IT assists users in identifying faulty agent behaviors.
"You just can't go around killing people" Explaining Agent Behavior to a Human Terminator
Apr 06, 2025


Consider a setting where a pre-trained agent is operating in an environment and a human operator can decide to temporarily terminate its operation and take-over for some duration of time. These kind of scenarios are common in human-machine interactions, for example in autonomous driving, factory automation and healthcare. In these settings, we typically observe a trade-off between two extreme cases -- if no take-overs are allowed, then the agent might employ a sub-optimal, possibly dangerous policy. Alternatively, if there are too many take-overs, then the human has no confidence in the agent, greatly limiting its usefulness. In this paper, we formalize this setup and propose an explainability scheme to help optimize the number of human interventions.
SySLLM: Generating Synthesized Policy Summaries for Reinforcement Learning Agents Using Large Language Models
Mar 13, 2025



Policies generated by Reinforcement Learning (RL) algorithms can be difficult to describe to users, as they result from the interplay between complex reward structures and neural network-based representations. This combination often leads to unpredictable behaviors, making policies challenging to analyze and posing significant obstacles to fostering human trust in real-world applications. Global policy summarization methods aim to describe agent behavior through a demonstration of actions in a subset of world-states. However, users can only watch a limited number of demonstrations, restricting their understanding of policies. Moreover, those methods overly rely on user interpretation, as they do not synthesize observations into coherent patterns. In this work, we present SySLLM (Synthesized Summary using LLMs), a novel method that employs synthesis summarization, utilizing large language models' (LLMs) extensive world knowledge and ability to capture patterns, to generate textual summaries of policies. Specifically, an expert evaluation demonstrates that the proposed approach generates summaries that capture the main insights generated by experts while not resulting in significant hallucinations. Additionally, a user study shows that SySLLM summaries are preferred over demonstration-based policy summaries and match or surpass their performance in objective agent identification tasks.
Examining the Prevalence and Dynamics of AI-Generated Media in Art Subreddits
Oct 09, 2024



Broadly accessible generative AI models like Dall-E have made it possible for anyone to create compelling visual art. In online communities, the introduction of AI-generated content (AIGC) may impact community dynamics by shifting the kinds of content being posted or the responses to content suspected of being generated by AI. We take steps towards examining the potential impact of AIGC on art-related communities on Reddit. We distinguish between communities that disallow AI content and those without a direct policy. We look at image-based posts made to these communities that are transparently created by AI, or comments in these communities that suspect authors of using generative AI. We find that AI posts (and accusations) have played a very small part in these communities through the end of 2023, accounting for fewer than 0.2% of the image-based posts. Even as the absolute number of author-labelled AI posts dwindles over time, accusations of AI use remain more persistent. We show that AI content is more readily used by newcomers and may help increase participation if it aligns with community rules. However, the tone of comments suspecting AI use by others have become more negative over time, especially in communities that do not have explicit rules about AI. Overall, the results show the changing norms and interactions around AIGC in online communities designated for creativity.
Explaining Reinforcement Learning Agents Through Counterfactual Action Outcomes
Dec 18, 2023



Explainable reinforcement learning (XRL) methods aim to help elucidate agent policies and decision-making processes. The majority of XRL approaches focus on local explanations, seeking to shed light on the reasons an agent acts the way it does at a specific world state. While such explanations are both useful and necessary, they typically do not portray the outcomes of the agent's selected choice of action. In this work, we propose ``COViz'', a new local explanation method that visually compares the outcome of an agent's chosen action to a counterfactual one. In contrast to most local explanations that provide state-limited observations of the agent's motivation, our method depicts alternative trajectories the agent could have taken from the given state and their outcomes. We evaluated the usefulness of COViz in supporting people's understanding of agents' preferences and compare it with reward decomposition, a local explanation method that describes an agent's expected utility for different actions by decomposing it into meaningful reward types. Furthermore, we examine the complementary benefits of integrating both methods. Our results show that such integration significantly improved participants' performance.
ASQ-IT: Interactive Explanations for Reinforcement-Learning Agents
Jan 24, 2023


As reinforcement learning methods increasingly amass accomplishments, the need for comprehending their solutions becomes more crucial. Most explainable reinforcement learning (XRL) methods generate a static explanation depicting their developers' intuition of what should be explained and how. In contrast, literature from the social sciences proposes that meaningful explanations are structured as a dialog between the explainer and the explainee, suggesting a more active role for the user and her communication with the agent. In this paper, we present ASQ-IT -- an interactive tool that presents video clips of the agent acting in its environment based on queries given by the user that describe temporal properties of behaviors of interest. Our approach is based on formal methods: queries in ASQ-IT's user interface map to a fragment of Linear Temporal Logic over finite traces (LTLf), which we developed, and our algorithm for query processing is based on automata theory. User studies show that end-users can understand and formulate queries in ASQ-IT, and that using ASQ-IT assists users in identifying faulty agent behaviors.
Dataset and Case Studies for Visual Near-Duplicates Detection in the Context of Social Media
Mar 14, 2022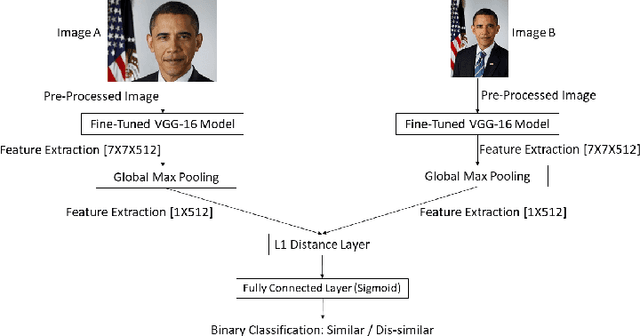
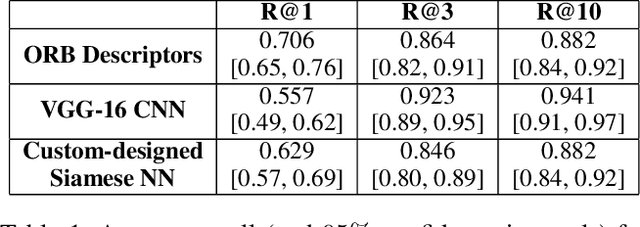

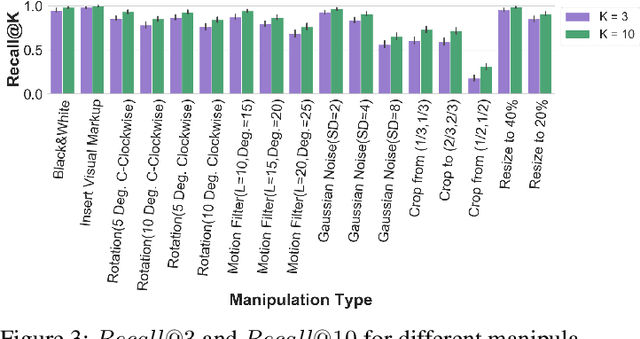
The massive spread of visual content through the web and social media poses both challenges and opportunities. Tracking visually-similar content is an important task for studying and analyzing social phenomena related to the spread of such content. In this paper, we address this need by building a dataset of social media images and evaluating visual near-duplicates retrieval methods based on image retrieval and several advanced visual feature extraction methods. We evaluate the methods using a large-scale dataset of images we crawl from social media and their manipulated versions we generated, presenting promising results in terms of recall. We demonstrate the potential of this method in two case studies: one that shows the value of creating systems supporting manual content review, and another that demonstrates the usefulness of automatic large-scale data analysis.
"I Don't Think So": Disagreement-Based Policy Summaries for Comparing Agents
Feb 05, 2021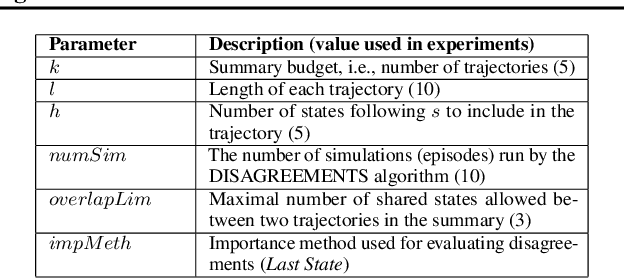
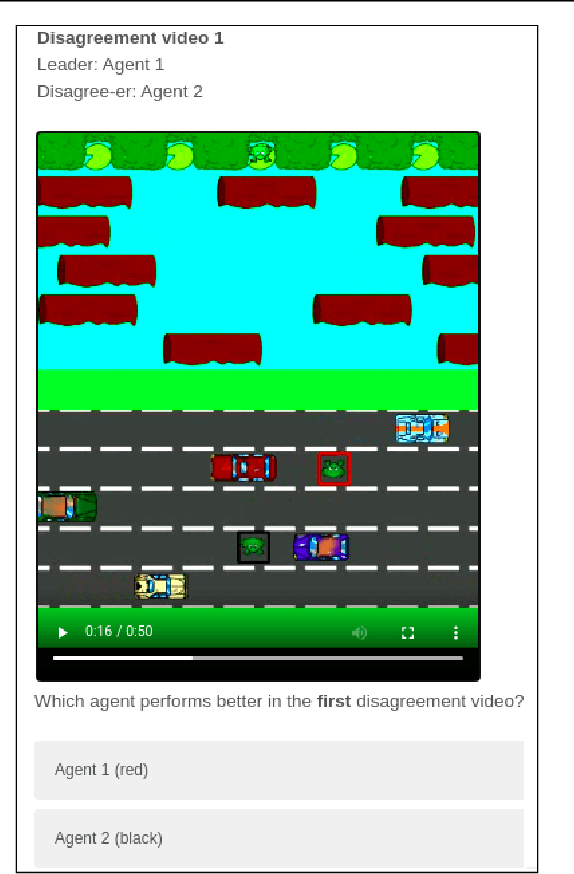
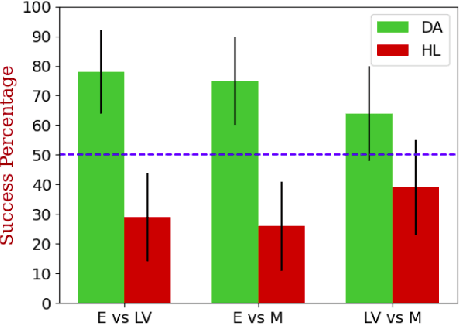
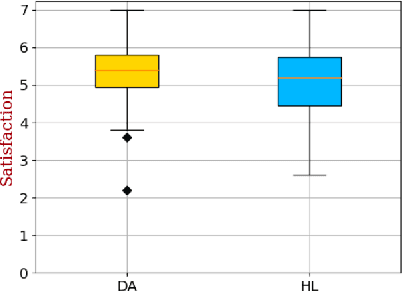
With Artificial Intelligence on the rise, human interaction with autonomous agents becomes more frequent. Effective human-agent collaboration requires that the human understands the agent's behavior, as failing to do so may lead to reduced productiveness, misuse, frustration and even danger. Agent strategy summarization methods are used to describe the strategy of an agent to its destined user through demonstration. The summary's purpose is to maximize the user's understanding of the agent's aptitude by showcasing its behaviour in a set of world states, chosen by some importance criteria. While shown to be useful, we show that these methods are limited in supporting the task of comparing agent behavior, as they independently generate a summary for each agent. In this paper, we propose a novel method for generating contrastive summaries that highlight the differences between agent's policies by identifying and ranking states in which the agents disagree on the best course of action. We conduct a user study in which participants face an agent selection task. Our results show that the novel disagreement-based summaries lead to improved user performance compared to summaries generated using HIGHLIGHTS, a previous strategy summarization algorithm.